
// Article - How to read values from a CSV file in Rungutan
Written April 15, 2021
Intro
A Comma Separated Values (CSV) file is a plain text file that contains a list of data. These files are often used for exchanging data between different applications. For example, databases and contact managers often support CSV files.
These files may sometimes be called Character Separated Values or Comma Delimited files. They mostly use the comma character to separate (or delimit) data, but sometimes use other characters, like semicolons. The idea is that you can export complex data from one application to a CSV file, and then import the data in that CSV file into another application.
source = How-To Geek
Why should I use it?
Parameterization is the process of creating multiple test data for single/multiple users in a test script.
Let’s say you have the task to load test the search functionality of the application — Wikipedia.
Since, it is a load test, you can not test it with a single search. In this case, you need to test it with multiple test data and hence you need to use the concept of parameterization.
So, instead, you should create a CSV file say “testData.csv” and then, for example, should you wish to search Continents in Wikipedia search page, fill a column with continents, and then use the file to randomly select one from the list and use it in your load test.
If that didn't help ring a ball, then how about for instance storing a long list of credentials (usernames/passwords), that you can then use in your load test system to impersonate users and test the loading mechanism of your platform?
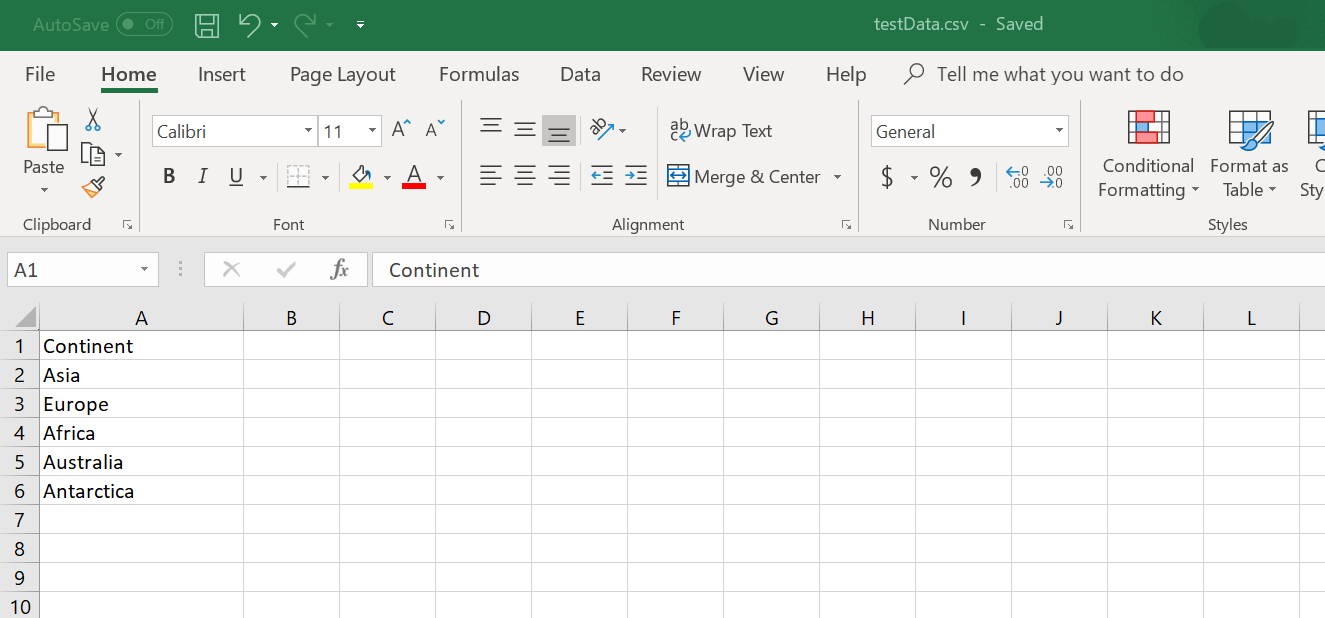
CSV feature specs in Rungutan
The CSV feature is a file-import based system which allows you to store ENCRYPTED-AT-REST comma-separated-value files containing relevant information for your test cases.
These files can then be imported in your test case workflow as following:
${csv.your_file_name_here.the_column_index_to_extract}
As you can see, it uses the same substitution logic as the one used for extracting/inserting worklow specific headers or responses into your test case, but having a specific namespace in front of it -> csv.
Our load test system extracts for each workflow step in which a CSV file is mentioned a random row from that file, fetches the column_index that you requested and substitutes the value inside the parameter.
The CSV file system can of course be used on the following properties:
- path
- header values
- data (payload)
Here’s how you would use a CSV file with the name csv_file_rungutan which extracts the column value with index 3 in your workflow as part of a path:
"workflow": [
{
"path": "/people/${csv.csv_file_rungutan.3}/profile",
"method": "GET",
"data": "",
"headers": {},
"extract": []
}
]
The column index starts at 0 of course so basically the “4th column” in your CSV file has the index 3.
The maximum size of a CSV file can be 10 MB.
Feature documentation
You'll be able to find of course more technical details and different methods of using this feature on our Documentation site at the CSV page.
The documentation covers everything, such as:
- What roles have access to perform what actions
- How to list/download/upload/remove CSVs from the WEB, using API calls or the CLI
How do I upload CSVs?
In order to upload a new CSV file, all you have to do is browse to the CSV page and click on the upload csv button.
Once you do that, you're presented with 2 options:
- A name = this will be the name you will use to reference the file in your workflow
- A path = the local file in your desktop that will be uploaded in our encrypted storage system
Once that is done, then the CSV page will be populated with your file and some metadata will show up according to your file's specifications, such as:
- File name
- Amount of rows that were detected in the file
- Amount of columns that were detected in the file
Bear in mind that we specifically make sure that you upload ONLY CSV files and that the file size is limited to 10 MB.
Don't worry, 10 MB is not that small. It should allow you to fill a CSV with almost 1.000.000 rows :)

How do I import CSVs?
As you probably already realized, there is nothing to import.
As soon as the file has been uploaded, it is immediately and readily available to be used in your test data.
CSV replacement in path
As we said, you can use CSVs to fetch and replace paths in your load test.
The usual scenario for such use case is when you have a list of UUIDs (maybe user IDs?) for which you want to test the API performance for loading its user details.
Here's how that would look like:
{
"test_name": "Update email + phone number - 1000 users csv",
"num_clients": 10,
"run_time": 60,
"threads_per_region": 5,
"workflow": [
{
"path": "https://example.com/user/${csv.testprod.3}/profile",
"method": "GET",
"data": "",
"headers": {
"Content-Type": "application/json",
"Authorization": "${vault.api_key}"
},
"extract": [
{
"parameter_name": "profile_id",
"location": "body",
"key": "profile_id_extracted"
}
]
},
{
"path": "https://example.com/user/${profile_id_extracted}/profile-details",
"method": "POST",
"data": "{\"phone_number\": \"+14041234567\"}",
"headers": {
"Content-Type": "application/json",
"Authorization": "${vault.api_key}"
}
},
{
"path": "https://example.com/user/${profile_id_extracted}/profile-details",
"method": "POST",
"data": "{\"email\": \"[email protected]"}",
"headers": {
"Content-Type": "application/json",
"Authorization": "${vault.api_key}"
}
}
],
"test_region": [
"us-east-1",
"us-east-2"
]
}
TL;DR -> The test above references the file testprod in the 1st workflow step, and afterwards, based on the profile ID it extracts from the API response of /user/USER_ID_FROM_CSV/profile, it then proceeds to update the phone number and the email address of that user.
Here's the step by step long explanation:
- First workflow step:
- Extract a random ROW from file testprod
- From that ROW, get the value of the COLUMN with index 3
- With that value, construct the URL -> /user/${csv.testprod.3}/profile
- Hit that URL with the METHOD GET
- Authenticate the API request using a VAULT key with the name api_key by placing it in the header key called "Authorization"
- EXTRACT the parameter profile_id from the received JSON response and STORE IT with variable name profile_id_extracted
- Second workflow step:
- Use the value of the PREVIOUSLY STORED variable profile_id_extracted and construct the URL -> /user/${profile_id_extracted}/profile-details
- Hit that URL with the METHOD POST
- Authenticate the API request using a VAULT key with the name api_key by placing it in the header key called "Authorization"
- Push the appropriate PAYLOAD using the json-escaped data field in order to update the phone number
- Third workflow step:
- Use the SAME value of the PREVIOUSLY STORED variable profile_id_extracted and construct the URL -> /user/${profile_id_extracted}/profile-details
- Hit that URL with the METHOD POST
- Authenticate the API request using a VAULT key with the name api_key by placing it in the header key called "Authorization"
- Push the appropriate PAYLOAD using the json-escaped data field in order to update the email address
CSV replacement in payload
Yes, you can reference values from CSVs inside the payload ("data" field) as well.
The most common use-case for this is logging in to systems with different usernames and passwords in order to understate how the API performance is affected with different profile data.
Here's how that would look like:
{
"test_name": "Log in and view orders on e-commerce website",
"num_clients": 10,
"run_time": 60,
"threads_per_region": 5,
"workflow": [
{
"path": "https://example.com/login",
"method": "GET",
"headers": {
"Content-Type": "application/x-www-form-urlencoded"
},
"extract": [
{
"parameter_name": "csrftoken",
"location": "body",
"element_find_regex": "meta name=\"csrf-token\" content=\"(.+?)\""
}
]
},
{
"path": "https://example.com/login",
"method": "POST",
"headers": {
"Content-Type": "application/x-www-form-urlencoded"
},
"data": "email=${csv.testprod.0}&password=${csv.testprod.1}&csrftoken=${csrftoken}",
"extract": [
{
"parameter_name": "auth_code",
"location": "header",
"key": "SESSION"
}
]
},
{
"path": "https://example.com/profile/orders",
"method": "GET",
"headers": {
"SESSION": "${auth_code}"
}
}
],
"test_region": [
"us-east-1",
"us-east-2"
]
}
TL;DR -> The test above simulates logging in an E-Commerce website, by first fetching the CSRF token on the login page (with GET method) on the initial request, then using that alongside the username/password combination extracted from the CSV to perform the login and extract the session from the SESSSION header and then using it in the third step to view its active orders.
Here's the step by step long explanation:
- First workflow step:
- Hit the login URL with the METHOD GET
- EXTRACT the CSRF token value by scanning the page for the actual value of csrf-token and STORE IT with variable name csrftoken
- Second workflow step:
- Use the value of the PREVIOUSLY STORED variable csrftoken and construct the LOGIN credentials by fetching the username and password from the CSV file testprod which are stored in columns with indexes 0 and 1 respectively
- Hit that URL with the METHOD POST
- EXTRACT the SESSION header value and STORE IT with variable name auth_code
- Third workflow step:
- Use the SAME value of the PREVIOUSLY STORED variable auth_code and place it in the SESSION header
- Hit the orders URL with the METHOD GET
CSV replacement in headers
Of course you can use CSV values inside header values!
This is not a very common use-case however, we can easily represent it as following:
{
"test_name": "Test API calls with different headers",
"num_clients": 10,
"run_time": 60,
"threads_per_region": 5,
"workflow": [
{
"path": "https://example.com/api/v1",
"method": "POST",
"headers": {
"Content-Type": "application/json",
"SomeHeader": "${csv.first_header_list.0}"
},
"data": "{\"random\": \"payload\"}",
},
{
"path": "https://example.com/api/v2",
"method": "GET",
"headers": {
"Content-Type": "application/json",
"SomeOtherHeader": "${csv.second_header_list.0}"
}
}
],
"test_region": [
"us-east-1",
"us-east-2"
]
}
TL;DR -> The test above simulates a workflow in which 2 API calls are made, each with a different header value, first being from a file called "first_header_list" and the other called "second_header_list".
Here's the step by step long explanation:
- First workflow step:
- Hit the /api/v1 URL with the METHOD POST
- Extract the index 0 of a random row from file first_header_list and reference it as a value for header with key SomeHeader
- Second workflow step:
- Hit the /api/v2 URL with the METHOD GET
- Extract the index 0 of a random row from another file called second_header_list and reference it as a value for header with key SomeOtherHeader
Final thoughts
Now you can easily reference different authentication systems or easily push huge chunks of data into your load test in order to actually test the stress level of your platform!